How LLM generates text
LLM (Large Language Model) has become an essential part of our life. When we perform a Google search, an AI generated result will show up at the top. In this era, it’s hard to say there is someone who uses internet but hasn’t used AI in some way. However, do you understand how LLM actually generate things?
LLM is able to generate many different things, including text, pictures, videos. In this post, we will go through the process of the text generation process.
For LLM to generate text, it has to go through 5 steps:
- Tokenization
- Embedding
- Transformation
- Probabilities
- Sampling
Let’s understand this process with an example. Imagine we ask ChatGPT: “What’s your name?”, and ChatGPT responds “My name is ChatGPT”. What happens behind the scene.
1. Tokenization
When the prompt “What’s your name?” is sent to ChatGPT, ChatGPT sends this prompt to the LLM (such as GPT-5). The tokenizer of the LLM will split the prompt by the token that it defines itself (different LLM has different sets of token).
We can explore how OpenAI models tokenize our input on the OpenAI tokenizer .

As we can see, the prompt is divided into 4 tokens. Each token also comes with a token ID, so the output of this step would be something like this: [45350, 634, 1308, 30].
2. Embedding
From step 1, we get a serious of token IDs. Following that, LLM will enrich the those IDs with more meanings (in this case, it’s called vector).
During the model training process, a token distribution pattern has been recognised by the statistical and lexical research. From that known pattern (again, the pattern identified by different models are also different), each token is attached to many vectors.
Let’s look at a simplified version. After the token is recognised, they will be placed in a diagram like this, from where we can get a coordinate. For example, for token “keyboard”, we will get a coordinate [2.8, 0.9]. This is called vector.
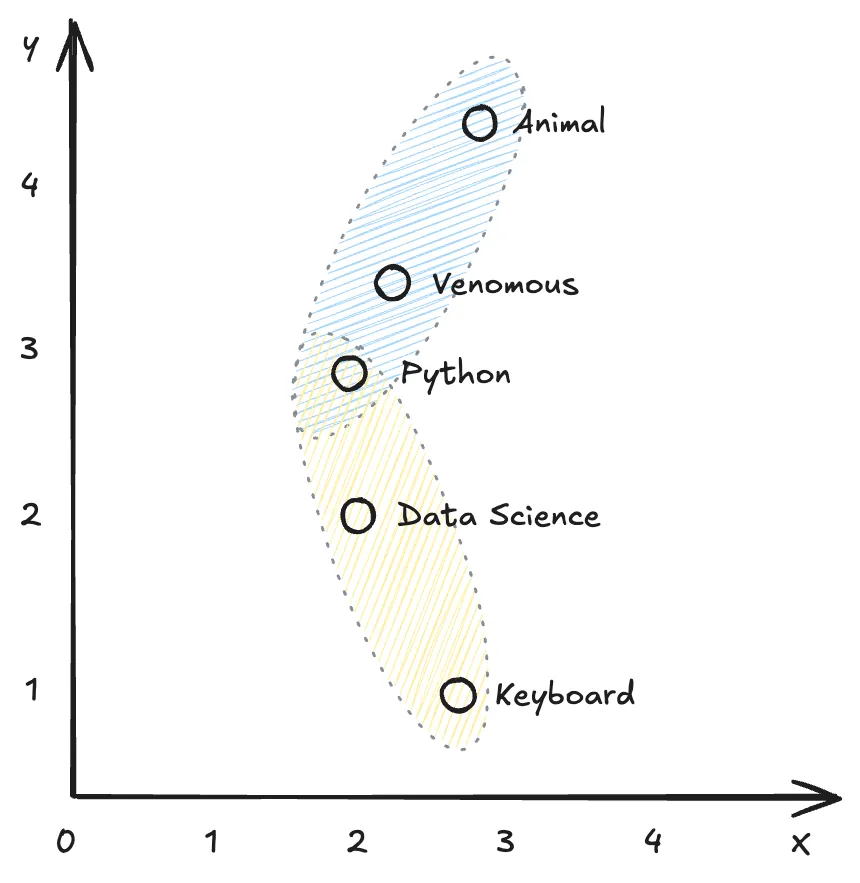
Since vectors are computable, later we can add Python with Animal, and hopefully we will get Venomous. This is a key part of the text generation of LLM. Just real LLM is never two dimensional.
Real LLM has much more dimensions. Here is a list of the embedding dimension of typical models.
| Model | Embedding dimension |
|---|---|
| GPT-2 (small) | 768 |
| GPT-3 (175B) | 12,288 |
| GPT-4 | Not officially disclosed |
| Llama 3 8B | 4,096 |
| Llama 3 70B | 8,192 |
| Claude models | Not officially disclosed |
This is a deterministic step. When the model gets trained, it maintains a table of token ID to vectors. This step is just a static query of ID to vectors.
So, for this step, our input is the token ID [45350, 634, 1308, 30], and the output will be something like this:
|
|
3. Transformation
The first two steps are kind of static query. It converts a string into many numbers (a list of double[]), but it is not context aware yet. For example, “Python” means both programming language and a venomous animal. In different context, it means differently. Before the step 3, for the token “Python”, we get the numbers here for both programming language and venomous animal, and this is going to be changed by transformer.
I am not knowledgable enough to explain how transformer works (actually I am not sure if anyone can explain what really happens). Just from the process point of view, the same process runs multiple times (for transformer, each iteration is called layer).
Layer 1 would be the raw input from the embedding query. Transformer takes those numbers and modifies them, so you might get something like this:
|
|
Eventually we get a transformed list of vectors. During this process, a few things happens:
- Attention is assigned (some token is less important than others; for example, in English, “the” isn’t important all the time)
- Relationship between token is understood (In an attributive clause, what does “which” stand for?)
- The meaning of each token becomes clearer (for example, is Python an animal or a programming language)
Layer is a pre-defined parameter of the model as well. Here is a list of the transformer layers of common LLM.
| Model | Transformer layers |
|---|---|
| GPT-2 Small | 12 |
| GPT-2 Large | 48 |
| GPT-3 (175B) | 96 |
| GPT-4 | Not disclosed |
| Llama 3 8B | 32 |
| Llama 3 70B | 80 |
| Claude models | Not disclosed |
4. Probabilities
As explained in the embedding step, vectors are computable. After transformation step, we still have a list of vectors. Based on those vectors, mathematical calculations can be performed, and we can get the probability of each token as the next possible token.
Back to our example, we asked ChatGPT “What’s your name?”. At this probabilities step, we can possibly get something like this:
| Possiblity of this token being the next token | Probabilities |
|---|---|
| My | 0.98 |
| I | 0.97 |
| I’m | 0.97 |
| The | 0.86 |
| … | … |
| Cat | 0.21 |
5. Sampling
The Probabilities step calculates the probability of every single token. In this Sampling step, a smaller subnet of the possible token will be sampled.
This is the last step of the generation step. It uses a parameter called “temperature”. If we use ChatGPT, we don’t directly control this parameter, but if we call OpenAI API to invoke the model directly, we can control it. Basically this temperature controls the threshold of the probabilities we accept. The higher the temperature is, the wider range of possible token we will select from.
Eventually, the next token will be selected randomly from the sampled tokens. Since the selection is random, that’s makes the result of generative AI random (given the same input, even the same model will generate different output in multiple runs).
Some readers might wonder why we don’t always choose the token of the highest probability. That is indeed a strategy, and it is called greedy decoding. This strategy usually brings about two major problems:
(1) local optimum: the best word at this position might not be the best word for the whole sentence. For example, “I am in a restaurant and I order…” might be followed by “food” instead of “spaghetti” or “fried rice” in greedy decoding.
(2) Repetitive loop: the generated text might start rounding in circle. For example: “Do verify this change, I am going to run terraform plan. This is a safe command that I am comfortable to run. This is a lovely command that I endorse. This is a harmless command that I should run. This is a great command that I praise…” (infinite loop, never stop - this is my real story with a Gemini model).
Repeat
After step 5, imagine “My” is chosen as the next token. Now the input becomes “What’s your name? My”, and then we repeat step 1-5, and a new token is generated and appended. This process repeats until an EOF signal is generated.
So, when you see ChatGPT displays its response word by word, it’s not just an animation. It is also how the model actually generates them.
Note
In this post, sometimes words and tokens are mixed; however, they are not the same thing. An English word could be divided at an arbitrary position into multiple tokens. For example, OpenAI GPT-5.x & O1/3 models split “Kubernetes” into 2 tokens: “K” and “ubernetes”.